
This paper represents part of a project, the goal of which is to create a rule-based morphology model that takes into account language regularities as far as possible and does not depend on technical restrictions imposed by the computer. The project is based on the open language model according to which all regular and productive phenomena of the natural language are represented by different types of rules, while exceptions are listed in small dictionaries called exception lists. This approach provides an opportunity to process those regular words that are not listed in dictionaries, i.e. new derivatives, compound words, loanwords etc.
From the units point of view the morphological system can be regarded as consisting of the following levels:
A rule-based model of morphology requires some formal rules and corresponding exception lists for each level. Today there exist formalised rules for three levels. The formation of word forms is described in the grammar part of the Concise Morphological Dictionary (= CMD) [6,7] and is also implemented on computer [1,4]. The most productive derivation rules are listed in CMD. The spelling checker for Estonian EEDI [2] contains the rules for compounding.
But there is as yet no comprehensive, statistically founded formal description of the Estonian stem changes that could be implemented on a computer. Stem changes are handled in dictionaries (ÕS, CMD) by listing all possible stem variants of each headword. CMD contains over 36,000 headwords, each of which has two stem variants on the average (the number of possible stem variants can vary strongly in Estonian: in some inflection types there are no stem variants at all, whereas in some others there can be as many as five different ones).
The present work attempts to fulfil the gap by presenting tools to create a formal description of the Estonian stem changes.
The Estonian morphology is characterised by the variation of all morphological units. In stem changes several kinds of variation can occur simultaneously. In some cases the stem remains unchanged, in some cases the change involves just phonetic quantity, but in most cases either the stem-end or stem-grade changes or both take place. Figure 1 depicts the classification of CMD vocabulary according to stem changeability.
Words with the similar phonological structure can suffer different
stem changes (cf. asi \thing\ - asja - asja, susi \wolf\
- soe - sutt and musi \kiss\ - musi - musi
).
Figure 1. Partition of the CMD vocabulary
There is no direct correspondence between a stem change and a
particular inflection. The rules are similar for noun and verb
morphology, as well as for derivation (cf. pank \bank\
- panga; hankima \to obtain\ - hangib; vanker
\castle\ - vangerdama \to castle\).
The principal types of changes are the following:
Our classification of the stem changes is summarized
on Figure 2.
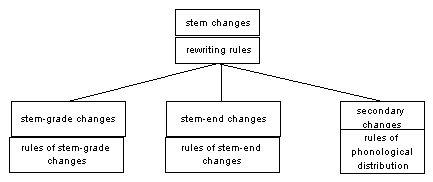
Figure 2. Classification of the stem changes
To attempt a systematic review of the stem changes we first need a detailed (incl. statistical) analysis of all stem changes registered. Such an analysis, in turn, requires a database containing the stem changes for each pair of a lemmatic stem and an inflection. The database can be created from CMD by adding a recognition system which for each pair of stem variants is able to decide what kind of a stem change holds between them. The features considered by the recognition system are in some respects different form those used by the human experts. For instance, the second and the third degree of phonetic quantity cannot always be differentiated by mere orthography unless the source text is not specially tagged. Certain historical and traditional criteria, that may sometimes be quite important for linguists can hardly be formalized at all.
Formally the recognition of stem changes can be reduced to a classification task with string pairs as the objects to classify and possible rules of stem changes as the classes. The system has to create class descriptions from the 'available' data: characters and their belonging to certain sound classes. An important requirement to the classification system is linguistic correctness. This is why the technique of inductive supervised learning is the best suited for our task.
Inductive supervised learning (learning from examples) is one of the main techniques in machine learning. Given a set of examples and counterexamples of a class the learning system induces a general class description that covers all of the positive examples and none of the counterexamples.
Most of the learning algorithms assume attribute-value pairs as input, with a fixed number of attributes and a known set of values for every attribute. In the case of data presented as strings class is often defined by a substring varying in length. The determinant role belongs to the main attribute (in our case, character corresponding to the changing sound) and its direct environs i.e. its context that consists of complement attributes. In most cases the width of the determining context is unknown at first, so the learning system has to deal with an undefined number of attributes.
In other words, inductive learning consists in the formulation of a description hypothesis, followed by an example-by-example adjustment process. The description is not accepted until it covers all of the positive examples and none of the negative ones.
The main specifying operation in the case of string data is the adding of an attribute - extending the context. As the length of the strings can be very different and in most cases the strings are relatively long, the learning direction towards expanding the context is preferable. The other way, i.e. to consider all string as context at first and try to specify the class description by dropping the redundant attributes is much more complex (complexity depends directly on the string length).
Depending on the domain the string alphabet can be divided into hierarchical classes. In this case, class descriptions can be generalized in terms of domain specific classes (sound classes in the present case).
The following algorithm is designed to find a class description for each of the seven formal stem changes:
The first six rules correspond to the stem-grade changes, while
the last applies to the stem-end changes.
The main alphabet:
S ={a,b,d,e,f,g,h,i,j,k,l,m,n,o,p,r,s,š,z,,t,u,v,õ,ä,ö,ü}
Alphabet of the sound classes:
D ={Z,W,C,Q,M,L,H}
The main alphabet is divided into the following subsets::
vowels={a,e,i,o,u,õ,ä,ö,ü}
consonants={b,d,f,g,h,j,k,l,m,n,p,r,s,š,z,,t,v}
voiced_consonants={j,l,m,n,r,z,,v}
voiceless_consonants ={b,d,f,g,h,k,p,s,š,t}
stops={b,d,g,k,p,t}
non_stops={f,h,s,š}
Z stands for a character from the main alphabet
W stands for a character from the vowels subset
C stands for a character from the consonants subset
L stands for a character from the voiced consonants subset
H stands for a character from the voiceless consonants
subset
Q stands for a character from the stops subset
M
stands for a character from the non-stops
subset
In addition, two special characters are used:
# for the end of a word
e
for an empty string
The sound classes are organized hierarchically (Figure
3).
Subscripts denote the equality of characters: Q1Q1
marks two equal stops (pp,kk);
W1W2
marks a diphthong (ae,ai, ...). The lack of subscripts
denotes that equality is not essential (WW
may stand for a long vowel aa as well as for a diphthong
ai ).

Figure 3. Hierarhcy of
the sound classes
The seven formal stem changes described above make up the set of classes. As at the same time only one of these can be recognized it seems appropriate to join the individual class descriptions into a decision list covering the whole set of examples. The decision list is a sequence of if then... else... clauses arranged according to the generality level of the conditions, while the last condition (class description for the stem-end changes in the present case) is the constant true. In other words, if no stem-grade changes are observed between two stem variants, the stem-end change holds between them.
For each stem-grade changing rule the system has to create a description
differentiating the stem variant pairs it applies to from the
rest of such pairs. The main attributes are the characters corresponding
to the changing sound in the first string and the characters in
the same positions of the second string. Consequently, the description
can be represented as a conjunction of the conditions:
ai Î
W
& bi Î
Q
& ...
To make the class description more lucid the conjunction can be presented as a phonological pattern.
Phonological pattern is an aligned pair of strings in the sound class alphabet, corresponding to the phonological structure of the variable part of the stem variants. To establish the corresponding phonological pattern the string characters standing for the sounds subject to change are separated and transformed from the main alphabet into the sound class alphabet. Phonological patterns are characterised by their cover extent, i.e. the number of string pairs to which the given pattern applies.
Unfortunately the pattern derived from the variable sounds only need not suffice to correctly establish the actual stem change. E.g. such pairs as
varre modernne
vars modernse
yield the same pattern
L1L1
L1 H
but actually are subject to different rules (rr®rs, ne®se). Therefore the pattern has to be extended. How wide the context to separate stem pairs belonging to different classes must be becomes evident only during the compiling of the description.
An extended phonological pattern (hereafter: pattern) is a phonological pattern extended to cover also the immediate environment (context) of the characters standing for the changing sounds and is represented by a triple

where a
and b
are strings in the sound class alphabet
and s denotes the position of the character corresponding
to a changing sound in the pattern (in string a).
A discriminative pattern
is a phonological pattern (either extended or not) which does
not cover any string pair belonging to the counterexamples.
Complement pattern are such phonological patterns that differ in a single element, while the difference is between two immediate offsprings of one and the same node in the sound class hierarchy, e.g.
WW WW
WQ WM
An inductive learning system needs a domain expert to predefine the possible classes and provide each class with examples, i.e. objects belonging to this class. Usually the counterexamples, i.e. objects which do not belong to the class are supplied too.
In the present work positive examples are the stem variant pairs subordinating to current stem changing rule. Counterexamples are the positive examples of all remaining classes.
For the selection of examples it is important to guarantee that all different sounds that can participate in a certain type of change were represented. In the opposite case the resulting description may turn out inadequate. If, for instance, the positive examples for the rule loss of one character include the pairs: uba-oa, lagi-lae, pida-pea, but miss out käsi-käe, the system will conclude that the main class-defining attribute is just a stop.
To avoid such occasionality, each stem variant pair with different
pseudosuffixes (the final part of the stem) were included in the
set of examples. The example set was then submitted to the domain
expert who provided each example with a class tag (Figure 4).
Figure 4. Tagged examples (tag number corresponds to the serial number in the list of the formal stem changes described above)
The initial description hypothesis is a disjunction of phonological patterns (not extended). This divides the sets of positive and negative examples into subsets conforming to different patterns. Discriminative patterns (if any) are added to the description and the corresponding subsets are removed from the sets of examples.
A phonological pattern can be extended in two directions: left,
towards the beginning of the word, and right, towards the end
of the word. Preferred is the direction in the case of which the
cover extent of the discriminative patterns is higher. If the
cover extents are equal, the left extension is chosen as according
to the domain specific heuristics the left context (that enfolding
the medial sounds) is more informative.
Given:
- A set of examples N={n1..nn}, in which each example is a triple nj=(a,b,z)
in which
a,b strings in the main alphabet (stem variants)
z position of the main attribute in the string a
(position of the character corresponding to the changing
sound in the first stem variant)
The set of examples falls into two disjoint subsets - positive and negative examples for each rule (N+ and N-, respectively):
N= N+È
N- & N+Ç
N-=Æ
- Function Get_Class, which maps strings from alphabet S into alphabet D according to the given hierarchy level t.
Get_Class: (a Î S* , t): a Î D*
- Sets of patterns P+={p1 ... pn} and P-= {p1 ... pm}, acquired from the sets of positive and negative examples
- The set C=  which is searched for under the condition Pn+
Ç Pn-
= Æ
which is searched for under the condition Pn+
Ç Pn-
= Æ
 denotes
the subset of examples conforming to pattern p;
denotes
the subset of examples conforming to pattern p;
p(n) pattern holding for n
a(p) component a of pattern p
· concatenation
of strings
STLearn
Init (P+, P-)
C=P+\P-
Update ( N+, N -, P+, P- )
While P+ Ç P- ¹ Æ
Get_left_context ( Pl+, Pl- )
Get_right_context ( Pr+, Pr- )
Select_successor (P+, P-, C' )
C=C' È C
Update ( N+, N -, P+, P- )
EndWhile
Optimize (C)
Procedure Init sets up the initial class of descriptions taking into account only the characters corresponding to the changing sound. By the initial patterns the sets of examples N+ and N- are divided into subsets corresponding to concrete patterns.
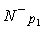 ...
... 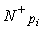 and
and  ...
... 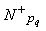
Init (P+,P-)
foreach n Î N+
if a(n)z(n)=a(n)z(n)-1 Ú b(n)z(n)=b(n)z(n)-1
a(p(n))=Get_Class(a(n)z(n)-1 ·a(n)z(n),3)
b(p(n))=Get_Class(b(n)z(n)-1 ·b(n)z(n),3)
s(p)=2
else
a(p(n))=Get_Class(a(n)z(n),3)
b(p(n))=Get_Class(b(n)z(n),3)
s(p)=1
Mark_Equal_Char(p)
if pÏP+
P+ = P+ È {p}
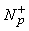 =
=
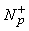 È
{n}
È
{n}
foreach n Î N -
if a(n)z(n)=a(n)z(n)-1 Ú b(n)z(n)=b(n)z(n)-1
a(p(n))=Get_Class(a(n)z(n)-1 ·a(n)z(n),3)
b(p(n))=Get_Class(b(n)z(n)-1 ·b(n)z(n),3)
s(p)=2
else
a(p(n))=Get_Class(a(n)z(n),3)
b(p(n))=Get_Class(b(n)z(n),3)
s(p)=1
Mark_Equal_Char(p)
if pÏP -
P -=P - È {p}
 =
= È {n}
È {n}
The procedure Update refreshes
the sets of examples. Discriminative patterns are added to the
class description and examples corresponding to them are removed
from the training set.
Update ( N+, N -, P+, P - )
foreach p Î P+
if p Ï ( P+ Ç P - )

P+ = P+ \ {p}
foreach p Î P -
if p Ï ( P+ Ç P- )

P - = P - \ {p}
Procedures Get_Right_Context
and Get_Left_Context extend the patterns by adding the
right and the left context to them, respectively.
get_right_context (Pr+, Pr-)
foreach ni Î N +
a (p(n))= a(p(n)) · Get_Class(a(n) z(n)+| a(p(n)) |+1-s,1)
b (p(n))= b(p(n)) · Get_Class(b(n) z(n)+| b(p(n)) |+1-s,1)
Mark_Equal_Char(p)
if pÏP+
P+ = P+ È {p}
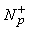 =
=
 È
{n}
È
{n}
foreach ni Î N -
a(p(n))= a(p(n)) · Get_Class(a(n)z(n)+| a(p(n)) |+1-s,1)
b(p(n))= b(p(n)) · Get_Class(b(n)z(n)+| b(p(n)) |+1-s,1)
Mark_Equal_Char(p)
if pÏP -
P - = P - È {p}
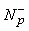 =
= 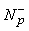 È {n}
È {n}
get_left_context (Pl+, Pl-)
foreach ni Î N +
a(p(n))= Get_Class(a(n)z(n)-s,1) ·a(p(n))
b(p(n))= Get_Class(b(n)z(n)-s,1) ·b(p(n))
s(p)= s(p)+1
Mark_Equal_Char(p)
if pÏP+
P+ = P+ È {p}
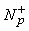 =
=  È {n}
È {n}
foreach ni Î N -
a(p(n))= a(p(n)) · Get_Class(a(n)z(n)+| a(p(n)) |+1-s,1)
b(p(n))= b(p(n)) · Get_Class(b(n)z(n)+| b(p(n)) |+1-s,1)
s(p)= s(p)+1
Mark_Equal_Char(p)
if pÏP -
P - = P - È {p}
 =
= 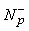 È {n}
È {n}
The next procedure selects the
better one of two extended patterns.
Select_successor (P+, P-, C' )
C'l = Pl+ \ Pl-
C'r = Pr+ \ Pr
If |C'l| =|C'r|
P+ = Pl+
P- = Pl-
C' = C'l
else
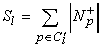
sr
=
If Sl > Sr
P+ = Pl+
P- = Pl-
C' = C'l
else
P+ = Pr+
P- = Pr-
C' = C'r
The last procedure generalises the final class description
by replacing the complement patterns with a more general common
one. The predicate
Compl_Pat (pi , pk ) is true, if
its arguments are complement patterns.
Optimize ( C )
for i = 1 to |C|-1
for k = i+1 to |C|
if Compl_Pat (pi , pk ) then
pi = Gen_Pat (pi , pk )
C = C \ {pk }
In addition, two auxiliary procedures are used:
Mark_Equal_Char supplies an index to those pattern elements that correspond to one and the same character.
Gen_Pat replaces complement patterns with an appropriate general one.
The STLearn algorithm is implemented on a IBM-486
computer using the software development environment Delphi.
The complexity evaluation of the algorithm for the worst case
is O( max(|ni| |N | +|C|2
).
Let us consider compiling the class description for the first class - deletion of a single character (Figure 5). For the sake of clarity this example contains but small subsets of positive and negative examples.
After the first step there is a single discriminative pattern (boldfaced in Figure 5):
Q
W
The pattern is added to the description under compilation and all examples covered by this pattern are left out of further consideration. The set of negative examples is cleansed of all examples covered by pattern
Q1
Q2
and work is continued only with those examples that are covered by patterns common to the positive and negative examples. Subsequently the description is modified by extending the context to the left and to the right by one character (columns 3 and 4). The cover extents of the extended patterns are equal. According to domain specific heuristics the left-hand extension is chosen and the pattern
WM
WW
is added to the class description. The next step again results in two different partitions (columns 5 and 6) in which discriminative patterns arise only in the left-hand extension. Patterns
WW Q WWM
WW# WW#
are added to the class description. As no more patterns common to the positive and negative examples are discovered the algorithm stops. As the last two patterns are complement they are replaced by the corresponding generalization:
WWH
WW#
The resulting class description for the first class is as follows:
if
Q or WM or WWH
W WW WW#
then class=1
| example |
| extension
to right | extension
to left | extension
to right | extension
to left | ||||||
| positive examples | |||||||||||
| viske#
vise# |
| ||||||||||
| lagi#
lae# |
| ||||||||||
| käsi#
käe# |
|
|
| ||||||||
| raag#
rao# |
|
|
|
|
| ||||||
| paas#
pae# |
|
|
|
|
| ||||||
| negative examples | |||||||||||
| aabe#
aape# |
| ||||||||||
| armsa#
armas# |
|
|
| ||||||||
| aetud#
aetu# |
|
|
|
|
| ||||||
| sipelgas#
sipelga# |
|
|
|
|
| ||||||
Figure 5. Compiling a sample class description
The examples of the remaining classes are processed the same way. The acquired class descriptions so obtained are ordered according to their level of generality (descriptions consisting of narrower patterns are more general) to form a decision list.
The decision list:
If L1L1 L1Q L1L1 L1 M #
L1Q or L1L1 or L1 M # or L1L1
then class=6
else if
H1 # C1 W Q1 W
H1 H1 or C1 C1 or Q2 Q2
then class=5
else if
H1 H1 C1 C1 Q1 Q1
H1 # or C1 W or Q2 W
then class=4
else if
Q1 Z QZ LZ H # L W
Q2 Z or LZ or QZ or LW or H #
CQ1W CQ2 # WWQ1 # WWQ2 W
CQ2 # or CQ1W or WWQ2 W or WWQ1 #
then class=3
else if
Q WM WWH
W or WW or WW #
then class=1
else if
W WW WW #
Q or WM or WWH
then class=2
else
class=7
Morphological and phonological phenomena are usually described by rewriting rules [3]. To make the present work adhere to this tradition the stem changing rules are represented in the following way:
This means that string a is to be replaced by (rewritten as) string b whenever it is preceded by Cl ( the left context) and followed by Cr (the right context). If the context consists of an empty string, it means that the context is not relevant to trigger the rule in question. If a is equal to an empty string, then the rewriting operation is reduced to one of insertion, while the same for string b means deletion.
As has been mentioned above stem variants can be connected by more than one stem change. E.g. the stem variants sepp \smith\ - sepa are subject to two rules:
Therefore a decision list should be cyclically referred to until all stem changes are identified. From the viewpoint of the modelling of the stem changing system of a natural language more information can be derived from rule sets holding for stem variant pairs than from single rules. In our algorithm a decision list compiled by STLearn is used as a shell for the identification of such rule sets.
Each established rule is immediately applied to the first string and the algorithm continues with an intermediate word form (that may not actually exist in the real language) until the first string becomes equal to the second. Domain theory says that in Estonian only one stem-end and/or stem-grade change can appear between a pair of stem variants.
As at rule recognition the string pair is parsed
from left to right a stem-grade change is usually detected before
a stem-end change. In case the rule set contains both types of
rules, the contexts usually need some correction, because there
are certain secondary changes in medial sounds that can take place
only after stem-end changes have been applied. To correct the
contexts the rules are once more applied in the right order (stem-end
change first) and the contexts are corrected.
Recognise-rules-algorithm
Let R= be the rule set wanted, a and b are the stem variants and r is the current rule.
2.1. add rule to the rule set R;
2.2. apply rule r to string a;
4.1. add the corresponding rule to the set R;
4.2. apply rule r to string a;
For the sample pair ütle-öel \to say\ the algorithm works as follows:
At the first step the deletion of the single character
(t® e)
is observed. The corresponding stem change rule t ®
e / ü_l is formed and added
to the rule set R.
The rule is applied to the string ütle
and work is continued with the intermediate stem pair *üle-öel.
As the two strings are not equal a secondary change is searched
for. As a corresponding phonological pattern is not observed the
algorithm returns to the first step and searches again for the
primary change. Observed is the stem-end rule
le®el
/ _# after the application of which work
is continued with the pair *üel-öel. At the next
step a secondary change of the lowering of the vowel ü®ö
/ _e is detected. After an application of the secondary
rule the strings become equal and the algorithm stops. As the
acquired set of rules contains more than one rule, the contexts
are updated. The resulting rule set for the pair of stem variants
ütle-öel is the following:
R={
R1 : le®el / _#
R2 : t®e / ü_e
R3 : ü®ö / _e ; R2
}
This way the rule sets for each stem variant pair are compiled. In addition, each rule is provided with its frequency of occurrence.
The aim of the current work is to create tools for the automatic recognition of the Estonian stem changes. The main problem consists in the bringing together of the formal classification features available to the computer (letters and their attributability to certain sound classes) and a classification based partly on unformalizable traditional and language historical criteria. E.g. in the string pair haudu-hau (d®e) an intervocalic d is deleted, whereas the string pair kareda-kare is subject to the transformation da®e.
The test results of the algorithms described in the present work show that it is possible to classify the stem changes by orthographic features and at the same time correctly in the linguistic sense.
The class descriptions were formed using 540 training examples. The recognition algorithm was tested on 56, 120 stem variant pairs, while not one linguistically incorrectly classified pair was observed. (From the initial test material 22 exceptional words had been removed by a domain expert.)
Analysis of the rule sets proves that a major part
of the Estonian stem variants are related only by a stem-end change,
or by a concurrent stem-grade and stem-end change (Figure 6).
| Frequency of occurrence (in CMD) | ||
| 2.66 | |||
| 83.82 | |||
| 13.10 | |||
| 0.14 | |||
| 0.25 | |||
| 0.03 |
Figure 6. Combination of the stem changes
Further work should provide the generalization of the acquired rule sets into a formal grammar in terms of sound classes and an elicitation of the corresponding exceptions lists. The resulting description should be adequate to the open model of language.